Today, most people sort through the deluge of information hitting the internet by filtering on topic (e.g. subreddit) or person (e.g. twitter follows, newsletters) or keyword (e.g. hashtags). There are not good ways to express complex, fuzzy preferences such as:
- summarized updates to active or pending legislation regarding gun control in jurisdictions which concern me, aggregated monthly
- newly listed vintage clothing in my size, within 15 minutes drive from my current location, daily
- published advanced in material science, once a week but in ELI5 language
- new remote jobs I’m qualified for
Such a system would need to:
- Turn the initial query into a list of feeds to monitor
- Evaluate feed items by the user instructions
- Aggregates hits in memory until their notification period comes again
- Create an email dispatch with suitable summary, aggregation and deduplication and analysis added in
- Take plain english comments from the user updating the standing instructions
The title of this article, dmonitors, is what I name the AI agents doing the filtering and packaging.
Details
Someone will build this. My citizens-lobby concept needs a version tuned for observations of the legislative process. There are important questions to resolve, first. How can you trust your assistant AI to serve your interests? For news, how are the analysis and journalists creating the articles compensated? How is spam, astroturfing or fraud mitigated?
If these AI agents decide what information you see, they have incredible individual and population level power. Markets can be moved and elections can be decided by a skew in information routing behavior. It’s temping to reach for some kind of open source solution where you’re able to plug your own AI model in front of the feed. I fear this is impractical for the vast number of people. Even if if you believe you’re running a certain model, it’s impractical to confirm the biases of the model, or that the model you expect is actually running without it’s input or output being modified by another process. Thus I believe technical orgs must be involved to steward this process, and their trustworthiness should be established through org structure, market competition and auditing.
The next issue is how to compensate authors. This does not matter for marketplace filtering, but it really does for news filtering. I contend even in the age of AI we’ll rely on people to gather and package information up before feeding into the filtering system I am describing. After all, useful information comes from people, not the void. People stake reputation on the quality of their output. They imbue it with the context of their identity. It’s critical authors are paid for their work so that they keep doing it. Otherwise the inputs to the feed will only be the kind of embedded advertising and propaganda authors are happy to distribute for free. There’s a related problem where the AI ingesting the raw articles need to be allowed access. Such an AI would usually be prohibited by robots.txt or by a paywall, and only with some kind of authentication would they be allowed in. Such access would likely only be granted if a fair compensation deal was created. (Aside: self hosted AI is the ultimate ad block, capable of digesting content and striping any ads before presenting it again - expect ad supported digital content to die soon)
You might imagine a paid subscription to information (e.g. NYT) solves this, but this has other problems. For one, it’s impractical for smaller niches. Furthermore, it’s harder for smaller sources or new authors to be discovered, as it would be most practical for users to keep paid subscriptions to a few established sources. Instead I propose that users pay a monthly fee to the org which runs the filter AI. This org, being trusted (see above), is be given access to information feeds from contributor orgs, for free, with the expectation any information actually passed on to the user yields a payment from the filter org to the contributor org.
Lastly, how is spam, astroturfing and fraud mitigated? Imagine a foreign state contributing divisive political news, or a hedge fund attempting to influence which stocks retail investors buy, or someone attempting to promote a pyramid investment scheme. I believe contributor org reputation works best. Orgs can be as large as a major newspaper or as tiny as a single person. What’s important is that they have a persistent credibility score which goes up when readers like what they read, and which goes down when readers flag it.As these are paying users, buying reputation would be expensive.
Ecosystem
Eventually, a health ecosystem has three tiers: end users, filter orgs (running the AI dmonitors) and contributors (surfacing information such as articles or listings)
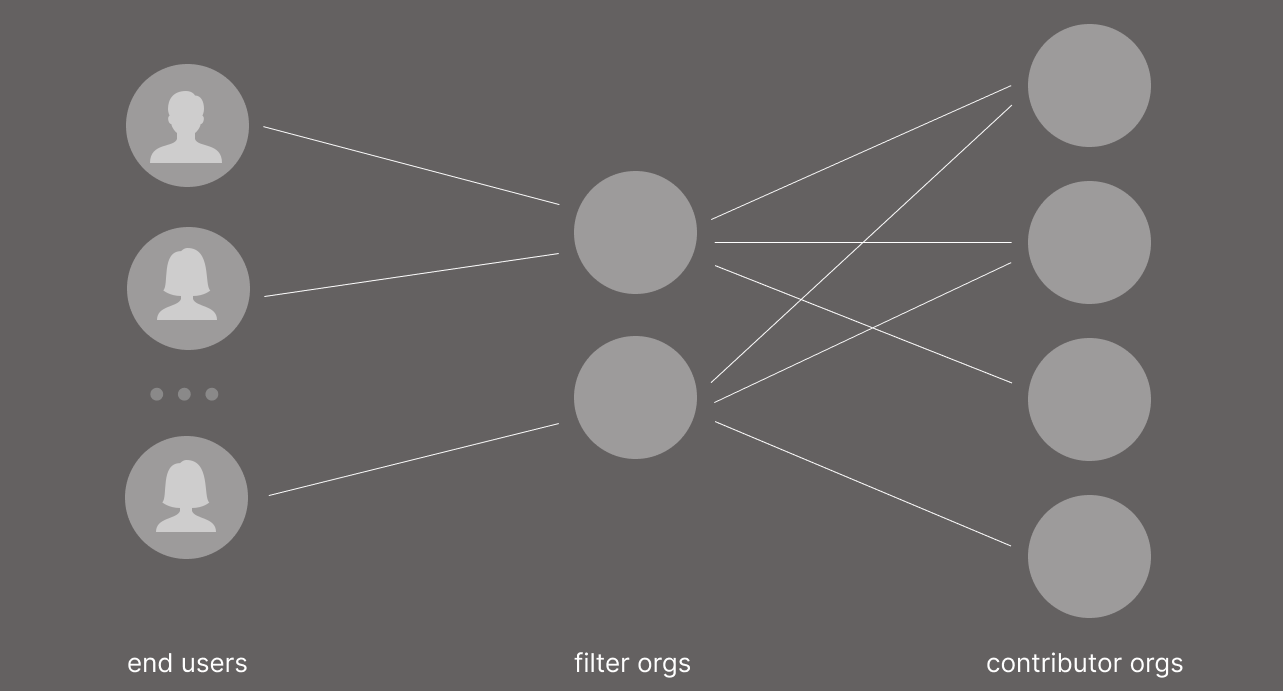
The first step is to create a filter org to take in information & articles from the existing web (rights allowing) running dmonitors internally to filter and aggregate data on behalf of end users. Suitable information sources available today include eBay’s free API, Reddits paid API, any free RSS source such as Craigslist. This is enough prototype the concept.
When we want to filter information which isn’t easily available over a free API (such as political news or updates on the machinations of government) the next step is to start a separate contributor org dedicated to surfacing that information. It should charge for access to its outputs, had have a license which suitably limits republishing, but of course allows automated access on behalf of end users. Then, a suitable filter org can be started up to filter that information on behalf or end users. Once there is enough money flowing through the filter org to the content org, additional contributor orgs can come into existence to go after it. The simplest case would be existing journalist organizations deciding to publish their articles over the protocol (with a suitable license) in exchange for fees from the filter org. It could snowball from there.
DMonitor Details
The end user spins up a dmonitor by with a query, and often, a paid subscription agreement. The dmonitor must take that query and create a model of what the user is interested in, how it should be presented, and how it should be bundled. There may even be nuanced preferences such as conditions when immediate notification is desired instead of waiting for the periodic information bundle. Thus, it’s likely the dmonitor agent will ask followup questions to the user at the start, and perhaps along with each future information delivery. Such learned preferences and user commands are stored.
The dmonitor will then create subscriptions to the information sources it knows about and believes to be relevant to the user. It will process updates from each one, and evaluate each item to understand if the user would be interested. If so, it accumulates it. When its time to send a bundle of information to the user, the dmonitor will check the accumulated articles and fashion them into a summary with outgoing links to full articles.
Related to this, one concept I’ve been thinking about is personal-agents. These are agents with a high degree of access to our personal life and environment, and likely run entirely locally on our phones and computers. It may well be that users don’t communicate directly to dmonitors, but instead that conversation is mediated by a personal agent. The personal agent knows a lot about their user’s preferences already, so they might be able to answer dmonitor questions without even bothering the user. This might also mean dmonitors can simply pass in the list of articles and leave it to the personal agent to summarize the information to the user. It could be the user preferences around the information feed become split, with the preferences about what information to look for living in the dmonitor, and the preferences about presentation and priority remaining in the personal agent.